

3天把Llama训成Mamba,性能不降,推理更快
2024-10-26 【 字体:大 中 小 】

编辑:alan
【新智元导读】近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。
先来看一张其乐融融的图片(一眼AI):

右边的小羊驼代表Llama,而左边的蛇(Mamba)也是我们的老熟人了。
至于到底能不能其乐融融,咱就不管了,之所以有此场景,是因为Mamba方面又搞出了有意思的研究:
——如何把Llama变成Mamba?

论文地址:https://arxiv.org/pdf/2408.15237
代码地址:https://github.com/jxiw/MambaInLlama
近日,来自康奈尔、普林斯顿等机构的研究人员推出了上面这篇工作,将Llama这样的大型Transformer提炼成了Mamba模型,
并且成功在Mamba架构上应用了带有硬件感知的推测解码算法,提高了整个模型的推理速度。
为什么要把Llama变成Mamba?
因为从头开始训练一个大模型太贵了。
Mamba也火了这么长时间了,相关的研究每天都有,但自己训练大尺寸Mamba模型的却很少。
目前比较有名的是AI21的Jamba(进化到了1.5版本,最大398B,MoE),以及NVIDIA的Hybrid Mamba2模型(8B)。

不过世界上有那么多成功的Transformer大模型,而知识就包含在这些模型参数里。
如果能够锁住知识,同时把Transformer微调成Mamba,不就解决问题了?
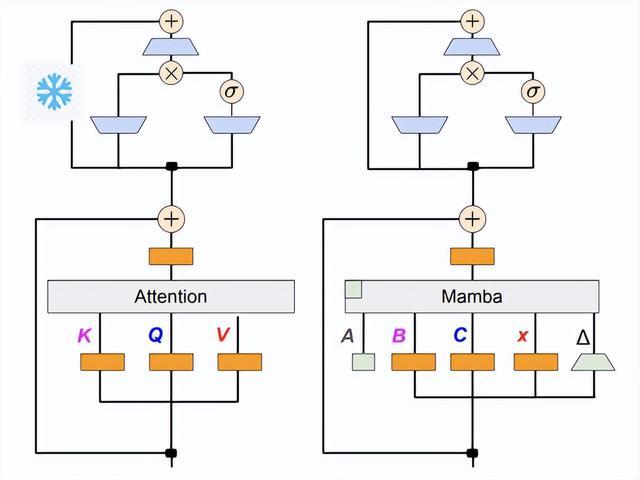
在本文中,研究人员结合渐进式蒸馏、监督微调(SFT)和定向偏好优化(DPO)等方法达成了这一目标。
光是变大还不够,
在性能匹配Transformer的前提下,速度也要够快才行。
Mamba凭借固定的推理开销,在长序列中的优势明显,但Transformer这边也是有推理加速方案的,比如推测解码。
而由于Mamba本身的结构特性,不能直接应用这种方案,所以作者设计了全新的算法,并结合硬件的性质来实现基于Mamba的推测解码。
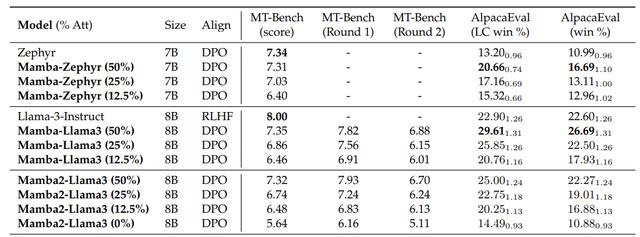
最终,研究人员将Zephyr-7B、Llama-3 8B提炼为了线性RNN模型(混合Mamba和Mamba2),且性能与蒸馏之前的标准模型相当。
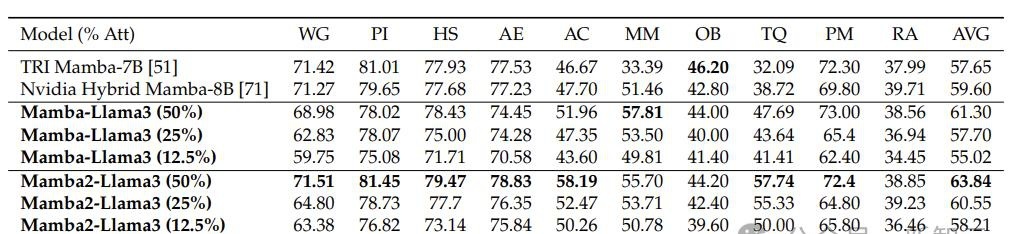
整个训练过程只使用了20B的token,效果却能够与使用1.2T个token从头开始训练的Mamba 7B模型,以及使用3.5T个token训练的NVIDIA Hybrid Mamba2模型相媲美。
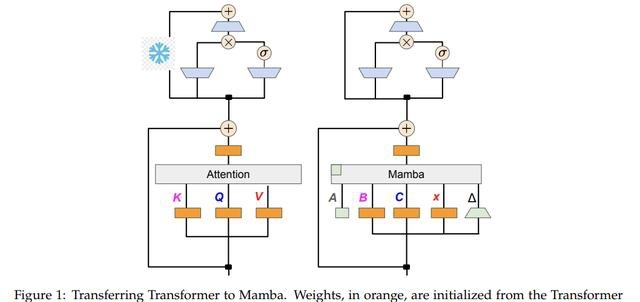
从 Transformer 到 Mamba
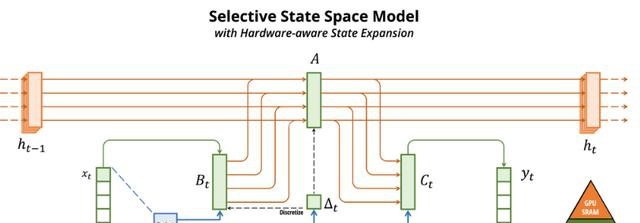
在介绍Mamba 2的时候我们讲过,线性RNN(或SSM)跟线性注意力是一回事。
所以可以根据x,B,C与V,K,Q的对应关系直接复用注意力中的投影矩阵。

额外的参数包括SSM需要的A矩阵和Δt(由x投影得到),这就完成了基本的参数初始化。
之后就是SSM的运算过程,再通过投影和累加得到输出。
模型架构和训练
下图给出了模型的架构,因为Transformer的知识存在于MLP层,所以冻结这部分参数。
除了用线性RNN层(Mamba)替换掉注意力头,还有一些组件需要处理,比如跨头共享键和值的分组查询注意力(GQA)。
知识蒸馏(Knowledge distillation,KD)是一种常用的压缩技术,用来训练模仿较大模型(teacher)行为的较小网络(student)。
根据经验,这里采用逐步替换Attention层的策略,先是每2层进行蒸馏,然后每4层继续蒸馏......
监督微调
有两种常见的蒸馏方法。一种方法是使用word-level的KL散度,此时训练student模型去匹配teacher模型输出的完整概率分布。
第二种方法是序列级知识蒸馏(SeqKD),直接使用teacher模型的输出作为ground truth来训练student模型(也称为伪标签)。
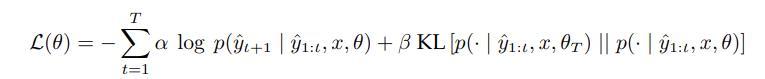
这里θ是student模型的可训练参数,α和β分别控制序列和词的loss项的权重。
偏好优化
LLM指令调优的第二阶段是使其符合用户偏好。这个阶段,使用一组期望的偏好对来改进模型的输出。
优化的目标是使奖励模型最大化,同时保持产生的输出接近参考模型。
通常,参考模型使用上一步监督微调后的模型。这里因为是蒸馏,直接可以用teacher模型:
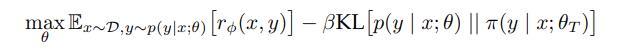
偏好模型的奖励函数定义取决于所使用的方法,本文采用直接偏好优化(DPO),通过直接梯度更新有效地到达优化目标。
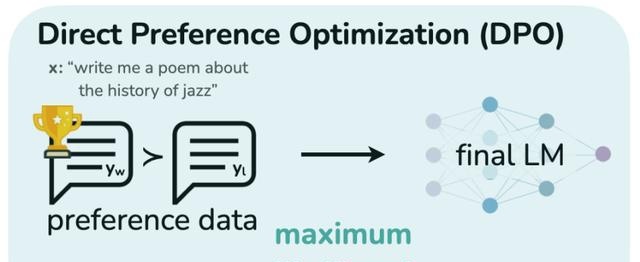
DPO表明,对于给定的提示x ,如果我们能够获得preferred和dispreferred两种输出,就可以将这个优化问题重新表述为:

这种优化可以在序列级别上执行,让teacher模型和student模型一起对preferred和dispreferred输出进行评分,然后反向传播给student模型。
推测解码
经过上面的一套小连招,模型转换就搞定了,下面开始想办法应用Transformer那边的推测解码。
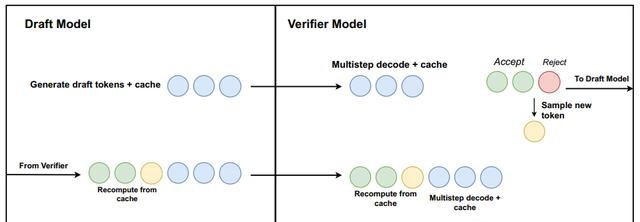
推测解码(Speculative Decoding)可以简单理解为下面这张图。
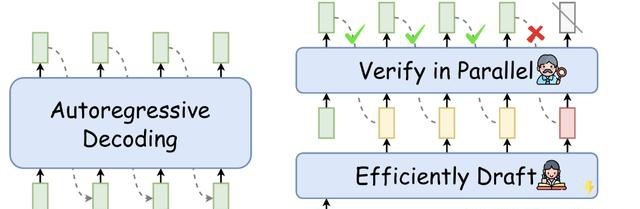
Transformer做推理的时候,除了要处理不断变长的KV cache之外,计算效率也是个问题。
因为显卡的设计是计算高于访存的,具体到计算单元就是做矩阵乘法。
而推理的时候每次只能进入一个词向量,显卡的很多计算就被浪费了。

推测解码给出的解决方案是,使用一个小模型做生成,然后拿显卡多余的计算做验证。
小模型跑得快,可以一口气生成很多输出向量,但是可能效果差一点。这时候用大模型作为验证,一次计算之前生成的很多个向量。
所以小模型串行跑得快,大模型可以并行计算跑得也快,遇到验证不通过的就直接回滚,整体上提高了推理的速度。
Transformer可以方便地回滚,因为KV cache跟时间是一一对应的,但Mamba这边只有一个当前的中间状态ht,你总不能把所有中间状态都存起来吧。
为了解决这个问题,研究人员设计了下面的算法:
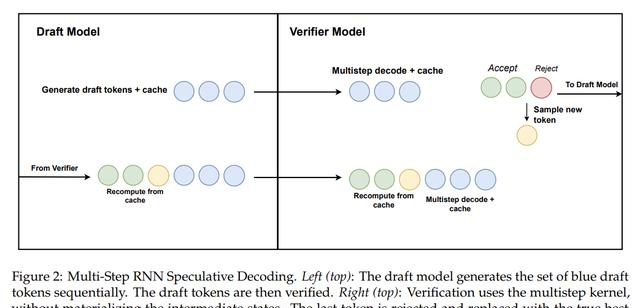
简单来说就是每次使用小模型(draft model)生成一组输出,然后大模型(verification model)验证这一组输出,根据验证匹配的位置来更新需要保存的中间状态。
我们可以从下面的伪代码了解详细的过程:

每次生成K个草稿输出,验证模型通过MultiStep函数返回K个真正的输出,以及上一次校验成功位置的cache(中间状态hj)和本次最后位置的cache(hk)。

Multi-Step内核的性能特征
通过FirstConflict函数找到最后匹配(校验成功)的位置,如果所有都匹配,则cache可以更新到最后的hk,否则就只更新到上一次的hj。
兵马后动,粮草先行,不耽误输出和校验,同时只需要多存储一个中间状态。
当然,如果草稿模型也用Mamba的话,算法的推测部分会变得复杂一些,因为草稿模型需要重新计算上一次迭代中验证成功位置的状态。
硬件特定优化
下面使用Mamba 7B和 Mamba 2.8B作为目标模型进行推测实验。
最初,作者搞了一版简单的算法实现,结果在Ampere架构的GPU(3090)上面效果显著,Mamba 2.8B获得了1.5倍的推理加速, 同时有60%的接受率。
但是这种实现方式在H100 GPU上不太好使,主要是因为GEMM操作的速度更快了,使得缓存和重新计算产生的开销更加明显。
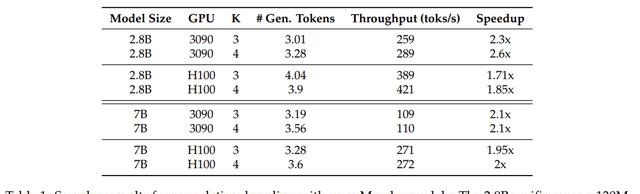
所以,作者通过融合内核以及调整实现方式来优化算法。
对于验证模型,首先从缓存中重新计算之前的步骤,然后对新的草稿token序列进行多步解码,最后在单个内核中进行缓存。
对于草稿模型,重新计算、解码和缓存也融合在单个内核中。最终实现了上表中的加速效果。
实验
研究人员使用两个LLM聊天模型进行实验:Zephyr-7B和Llama-3 Instruct 8B。
采用三阶段蒸馏。在第一阶段,使用UltraChat和UltraFeedback作为种子提示,并使用teacher模型生成伪标签。
使用AdamW优化器训练模型,β=(0.9,0.98) ,批量大小64。先使用线性学习率预热,然后进行余弦退火。
第二阶段,在一个epoch中使用SFT在GenQA、InfinityInstruct和OpenHermes 2.5数据集上对模型进行监督微调,采用与Zephyr相同的超参数。
最后一个阶段,对于从Zephyr中提取的模型,在UltraFeedback数据集上使用DPO与标准模型进行蒸馏对齐。
过程中只在第一阶段冻结MLP层,后两个阶段所有参数都进行训练。
作者表示,通常只需要在8卡80G A100上运行3到4天,即可重现本文的结果。

猜你喜欢

聚力保交楼:房企下半场靠健康新动力|楼市一线观
 5075
5075 需求将为金价提供坚实支撑,未来几天瞄准2065美元!
7928 奥运第五日看点: 全红婵陈芋汐联手上演“水花消失术”,中国女篮力争首胜
4006 金山办公首席执行官章庆元:重心是AI与协作
6151 别让TA偷走你的好“孕”气
1688 3月27日基金净值:新华增怡债券A最新净值13713,跌107%
1432 AI“数据荒”怎么办?微软、谷歌等公司正使用“合成数据”训练AI
4977 2024年2月6日全国主要批发市场牛价格行情
9010 全国首单商标海外布局费用损失保险落地广州
2610 美国重磅数据将揭晓!市场蠢蠢欲动,美联储料将如何回应?
514 









东吴期货投资策略早参20221116

海通证券净利润下滑7511%,IPO承销金额打“一折”

聚焦新质生产力、情绪价值,高品质消费品牌TOP100出炉

马鞍山钢铁股份有限公司注册资本(金)变更发生变更

下车请按铃!广州番禺区这些公交线路不再“站站停”

2001年朱镕基为何事专程探望清华学长熊向晖?

以进一步改革实现香港更好发展

德源药业:8月29日接受机构调研,开源证券、华夏养老等多家机构参与

雪糕界“爱马仕”贱卖至2元!创始人卖红薯也要还债,起底背后的商业版图!

官宣:香港警队最快7月25日起改用国产手枪

